次から次へとまあ。
河野太郎がマイナンバーカードの住所照合についてデジタル音痴ぶりを如何なく発揮した件
— 杉原航太 (@kota_sugihara) 2023年6月4日
河野大臣『問題は住所が「港区赤坂一丁目2の3」と書く人もいれば、「港区赤坂1-2-3」と書く人もいる…(中略)将来的にはAIの技術を使って表記揺れを判断することがあり得るかもしれない。』… pic.twitter.com/aF2jzwtBkN
デジタル音痴はおまえだ。
話題の表記揺れ問題。河野大臣は特に変なことは言っていない。
河野大臣:
AIを活用するまでもなく、ふりがなが振られれば、名前の照合はできる。名前、生年月日、マイナンバー、これらがきちんと照合されれば誤登録はなくなる。ただ、問題は住所が「港区赤坂一丁目2の3」と書く人もいれば、「港区赤坂1-2-3」と書く人もいる。「1-2-3」を半角で入れる人もいれば、全角で入れる人もいるし、ハイフンを「の」と入れる人もいる。将来的にはAIの技術を使って表記揺れを判断することがあり得るかもしれない。
松山キャスター:
住民基本台帳とマイナンバーとで住所表記を一元化できないのか。
河野大臣:
いまデジタル庁でベース・レジストリ(公的基礎情報データベース)というのを作っている。住所表記はこれに合わせるルールを作ると同時に、多少表記揺れがあっても紐付けできることを目指している。また、新規の入力をするときには、こういうルールでなるべくやってほしいと。自分で年賀状の住所録を作るときに「あれ、この人の住所、入っていたはずなのに」みたいなことがある。このベース・レジストリできちんとやっていければ、住所の表記揺れも突合できるようになる。
このツイートで知った。
システムを触ったことのある人なら秒でわかるはず、住所の表記揺れはすぐ解決できる問題ではないことに。全角と半角、漢数字と数字、丁目の有無な空白など、フリーフォーマットな記載から一意にするのは気の遠くなるような処理が必要なはず。 https://t.co/k6x3xa4YHt
— うめめ🔛ITエンジニンジン🐰 (@beConjuror) 2023年6月5日
サムネイル用。

オレもやったことあるからわかるけど、住所のデータクレンジングなんて住所用の汎用的なデータクレンジングツールだけでは100%OKにならない。絶対に一定割合で人間判断が入る。そのデータの出元にもよるけど100%どころか70%も怪しい。その残りで死ぬ。
河野大臣「住所の表記揺れは難しい」
— Henry (@HighWiz) 2023年6月5日
素人『住所の表記揺れなんて簡単😤』
表記揺れを舐めてるのかい?
それともすごく、舐めてるのかい?
死ぬほどダサいからツイ消しすべき案件。 https://t.co/kBZ0sZQKeN
簡単にできるぞ素人もHenry氏がツイートしてる。
『2時間で作れるからnoteで売るわ😤』
— Henry (@HighWiz) 2023年6月5日
あのさぁ…。 pic.twitter.com/W25H3tYerX
画像じゃなんなので探してみた。
そんなんExcelでええやん🤣
— 清水ひろあき@北九州市 (@shimihiro_kitaq) 2023年6月5日
いやいや普通に置換使えば一撃ではないけどある程度少ない工数でできると思うけど
— 清水ひろあき@北九州市 (@shimihiro_kitaq) 2023年6月5日
思いつきで適当に言うけど、例えば「丁目」「番」を置換で「-」にして、あとMIDで漢数字を抽出して一から順に並べてセルわけてFINDでアラビア数字にするとか。逆も然り。一回組んでしまえばずっと使えると思うんだけど、そんなに大変な何かがあるのかな、、、
— 清水ひろあき@北九州市 (@shimihiro_kitaq) 2023年6月5日
最初の処理だけでこれだけの地名にバグを生みますhttps://t.co/skbkV6gBRrhttps://t.co/2u5N2Z2E9t
— kzk_maeda | 6/24 Reject Day 2023!! (@kzk_maeda) 2023年6月5日
最初に町名以前と以後で入力セル分けとけばいいだけの話。てか、今時webフォームは殆どそうですけど。
— 清水ひろあき@北九州市 (@shimihiro_kitaq) 2023年6月5日
住所揺れを「AIを使って将来的にどうのこうの」って言ってる河野太郎さんの発言に対して「Excelでええやん」ってツイートしたら自称エンジニアさん達から袋叩きにあってるんだけど、この数式組んだら売れるんかな?2時間あれば作れそうだから儲かるかな? https://t.co/58jjQJlj0R
— 清水ひろあき@北九州市 (@shimihiro_kitaq) 2023年6月5日
ところでこいつアカウントも見つからない。Twitterの検索が死んでる説もあるけど。
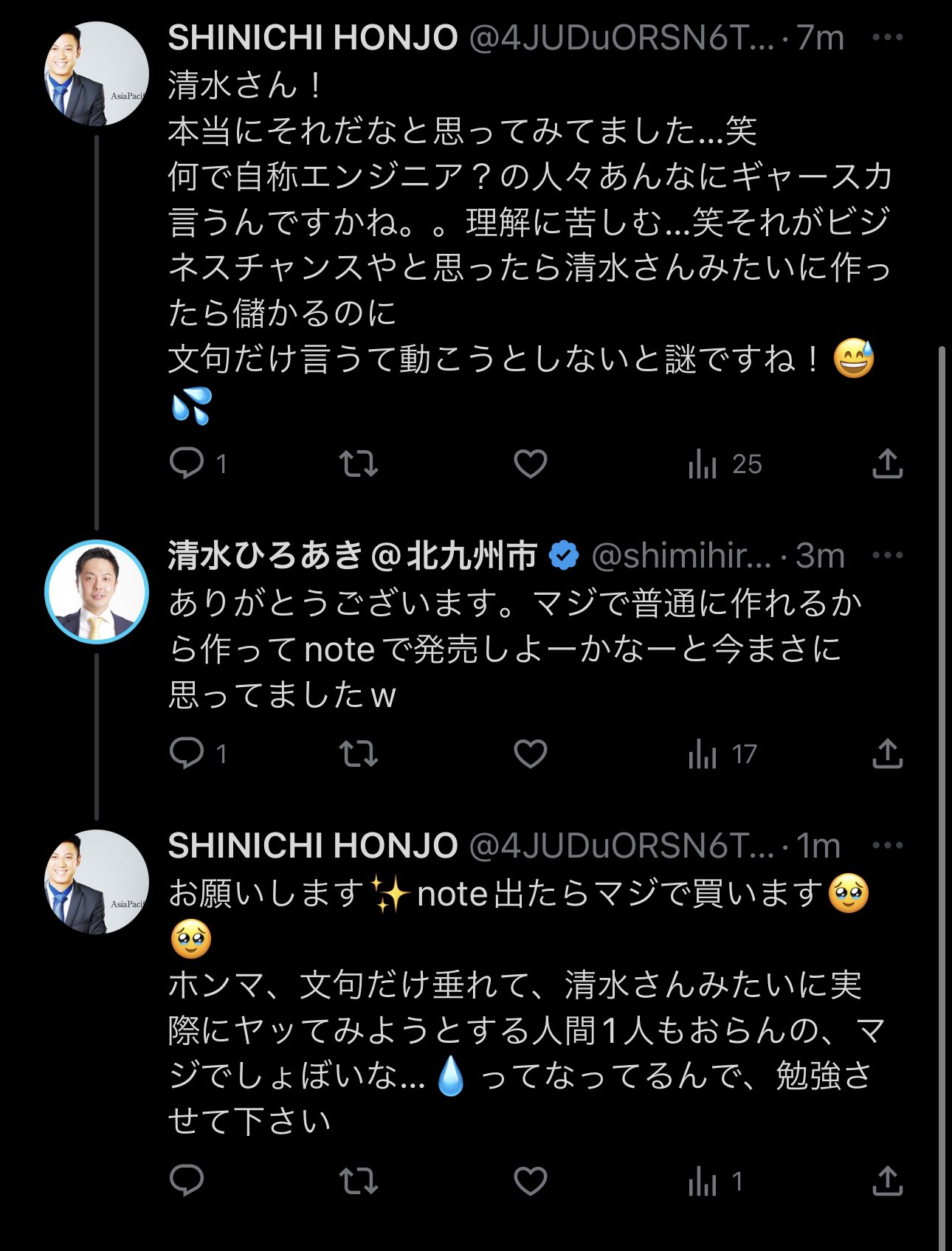
少なくともツイートは消してる。

このExcelデカンタンニデキルノニーさん、さてどうなったでしょう。
専用SaaSやGoogle APIが作られるレベルの課題にExcel関数で立ち向かう強者 https://t.co/JrKCmKAi6e
— kzk_maeda | 6/24 Reject Day 2023!! (@kzk_maeda) 2023年6月5日
そんなに難しいんですか?
— 清水ひろあき@北九州市 (@shimihiro_kitaq) 2023年6月5日
入力フォームの時点で階層わけて置換と簡単な関数で最後if errorとかで終わるんじゃないの?くらいにしか思ってませんでしたが、どうやらそうじゃないんですね。。
不勉強なので教えてください汗
「将来的にAI活用」するまでもなく始めから入力フォームで階層分けて置けばExcelの簡単な関数で出来るやんっていう超シンプルな意見ですが何か間違ってますかねぇ?
— 清水ひろあき@北九州市 (@shimihiro_kitaq) 2023年6月5日
これからの入力だけじゃなく、今あるデータをどうするかって話がメインであることさえ分かっていなかった。
この人が言っているのは局所的な「置換作業」に過ぎなくて、
— 無能なえる(心の声が聞こえます) (@ellnore_pad_267) 2023年6月5日
そんなもんはそりゃあ Excel だろうがなんだろうが出来るんだよね、そりゃね。
変換位置が複数あったら表計算関数だけだとダルいんであれだが、まぁ不可能ではない。
問題は「どこを置換すべきか」の検出ロジックの方。 https://t.co/e5hgx0HpGz
「都道府県」「市区町村」「丁目番地」で入力フォームわけとけばいいだけです。
— 清水ひろあき@北九州市 (@shimihiro_kitaq) 2023年6月5日
Excel で?
— 無能なえる(心の声が聞こえます) (@ellnore_pad_267) 2023年6月5日
画面作るんですか?
てっきりすでに入力された住所データの訂正の話かと思ってましたが。
ちなみに京都の通り住所とかの対応どうするんです?
北九州だから関係ない?
階層分けである程度の対応は可能ですけど、それってせいぜい住所コードで指定可能な途中の住所まで(せいぜい字・大字あたりかなぁ、ちょっと正確にはわからない)で、
— 無能なえる(心の声が聞こえます) (@ellnore_pad_267) 2023年6月5日
結局最後の方の住所・補助住所は人間が打つ。
人間がフリーダムに入力する部分がある以上、そこは静的定義セットだけでは困難。
なるほどー!!
— 清水ひろあき@北九州市 (@shimihiro_kitaq) 2023年6月5日
勉強になりました!
実際にそういうイレギュラーに悩んでる現場の皆さんの立場にならないと何事も理屈じゃわかりませんね!
失礼な受け答え申し訳ありませんでした汗
町名以前と以後で分かれてないRawデータを受け取った場合はどのようにロジックで町名以前と以後を分けますか?
— nyohhiroki (@nyohhiroki) 2023年6月5日
それはExcelじゃ無理ですね!
— 清水ひろあき@北九州市 (@shimihiro_kitaq) 2023年6月5日
浅はかでした!
住所のデータはすでに存在しているものが膨大にある。なので、入力フィールド分けるとかバリデーションで弾くとかという話を始めた瞬間に見る価値が無い。
この程度の簡単なやつなら市販のツールやサービスでもやれる。Excelでちょちょいと作れるわけじゃないけど。
足立区/北千住/1-2-3-401
— お昼休みは山上ウォッチン! (@itcon_09_review) 2023年6月5日
足立区/北千住1丁目/2-3/ハイツ曙401
足立区/北千住1-二番地/三号/ハイツアケボノ四〇一号室
この辺全部ケアできるnoteだったら買います!!!!
オレもちょいツイートしたけど、こういうイレギュラーデータや地名・建物名変更との闘いである。平仮名・片仮名・新字・旧字・異体字・歴史的仮名遣・漢数字・英数字などなど数え切れないパターンで、しかも入力している本人が一つの住所でも統一して入れてくれない可能性があるっていうのに。
住所の表記ゆれ、簡単なわけないだろ。
— ꧁🐶꧂ (@shigeo_t) 2023年6月5日
一丁目をIT目くらいの入力はあたりまえに混ざってるぞ。
ビルもヒ"ルとか普通にやってるぞ。
ヒ"ルとかやられると、CSVにした時半端に処理終了するぞ。
「ヒ"ル」はどういうデータかというとカナのヒに半角ダブルコーテーションである。これをCSVに含むと、……わかりますね。そこでCSVを扱うプログラム例えばExcelなんかはそのカラムが終わったと判断する。ダブルコーテーションを使う時は2つセットで囲むという決まりなので、途中にデータとしてダブルコーテーションが来るならエスケープする必要がある。
元々のデータの出元が何かでも特徴が分かれる。メインフレーム時代からの古いデータだと、こんな感じ。
- 上記ダブルコーテーションなど住所に無い記号を使っている
- 1-2-3、1-2-3と同じように1―2―3、1ー2ー3 が混在している
- 外字が使われている
- 光が丘、光ヶ丘、光ケ丘
2番目わかんないでしょ、コード的には別だけど。
メインフレーム時代からのデータは、もともと本人入力よりは紙で提出された申請書等を事務員が入力していたりする。なので、かな入力する職員が濁点の代わりにダブルコーテーション使ったりという変なクセを持つ人が入力した1番目や2番目のデータがある。さらにOCR入力もある。チェック漏れあれば変な住所が入っている。
また、本人入力じゃないので4番目のように事務員が思った表記で入力している。また、メインフレームの文字コード体系はEBCDIK/JIS系なのでコード一覧に無い漢字は外字として入力してきた経緯がある。Unicode化された時に外字から変換していなければなんか変な記号が入った住所となっている可能性がある。
じゃあUnicodeなら問題無いかと言えば、CJK互換漢字問題がある。
CJK互換漢字はその名前にもかかわらずCJK統合漢字と互換等価ではなく正準等価であり、互いに区別されることを期待してはならない。このため4種類の正規化のいずれを採用してもCJK統合漢字に分解(変換)されてしまい、日本の人名処理などにおいて要求されることのある一部の人名用漢字などの区別が、Unicodeのプレーンテキスト上で保証されるとは限らない。
一部にCJK互換漢字の等価性を正準等価から互換等価に変えるべきであるという主張があるが、UnicodeではJIS X 0213用の互換漢字の一部は新たに収録せず、既存のKS X 1001互換文字用の領域などに収録されていた文字を流用している。このため日本語だけの都合で等価性を変えることはできない。またUnicodeには正規化の安定性の原則があり、その意味でも等価性の変更は現実的ではない。
住所に使われることは少ないはずだが、例えば懲 と 懲 は見分けがつかない。日本語IMEを使っている人が入力すれば 懲 かもしれないが、ピンインで入力すると 懲 かもしれない。
というわけで、現在の住所用データクレンジングツールやサービスの自動変換から漏れて、人間が確認しないといけない表記揺れについてはAIを使うというのは合理的である。コードで比べると別物でも同じに見えたらどちらかに寄せるという処理を作れる。そういう意味ではChatGPTなどで話題のLLM大規模言語モデルだけでなく画像判別系を合わせ技で使うということもあるかもしれない。
まあ、河野太郎大臣の出した例が陳腐だからExcelデカンタンニデキルノニーが湧いたのかもしれないけど、住所の表記揺れは相当面倒である。某損保会社でやった時に使ったツールは数百万の奴(名称失念)だったけど、それまでの住所データの表記揺れについて集合知が詰まってた。それでも数%は処理できないデータがあった。Excelでできるならもうできてるって。

件のExcelデカンタンニデキルノニーさんのExcelだと、八戸が8戸になりそうで怖いw
品質要件と瑕疵担保責任と損害賠償請求に関する条項を盛り込んだ契約書を交わした上で、テストケースとテスト結果のエビデンスも揃ってるなら1000万円払います。 https://t.co/a8rhWpe5Fr
— Henry (@HighWiz) 2023年6月6日
これはお優しい。オレなら瑕疵担保責任と損害賠償請求に関する条項を盛り込んで変換作業発注する。半月1,000万円から2,000万円くらいの飛びついてきそうな金額で。
これもそう。専門家が頑張ってできていないんだから、できていない理由があるに決まってるじゃないか。
.@myo80766994 さんのコメント「再エネの効率化にしても蓄電の効率化にしても「どこかが開発した技術を輸入しよう」という話になっていない。これが何を意味するかわからないんだろうな。つまり、世界レベルで「メイン電力となりえる再エネ及び蓄電技‥」にいいね!しました。 https://t.co/orc1iUs15Q
— ꧁🐶꧂ (@shigeo_t) 2023年6月5日